|
Dirac Notation, Fock Space and Riemann Metric Tensor in Information Retrieval Models
Sherman Wang, PhD in Theoretical Physics Email: xmwang@shermanlab.com First Draft: 10/22, 2006 Second Draft: 12/03/2006
Introduction
Using Dirac Notation, various modern Information Retrieval (IR) models (vector space, Boolean, probabilistic and some their extensions) are investigated in Occupation Number Representations (ONR) of Fock spaces. A Riemannian metric tensor is derived based on Singular Value Decomposition (SVD) for Latent Semantic Indexing (LSI) Model.
This article is not about how to deduce models from first principals, but is about how to use Dirac notation and Fock space to investigate exiting models in a concrete way of representations. After finishing first draft, we notice that Van Rijsbergen has discussed ([19]) IR in an abstract way, using observables (Hermitian operators) and Hilbert space with Dirac notation. Whenever is possible, we will make use of and make comparison to Ref. [19].
Table of Contents
1.1. The Vector Space Model and Weighted Term Vector Space 1.2. The Boolean Model and Boolean Term Vector Space 1.3. Fock Spaces and Occupation Number Representations 1.4. Probabilistic Model and Term-Query Probability
2.1. The Fuzzy Set Retrieval and Fuzzy Boolean Term Fock Space 2.3. Term-Term Correlation and the Document Fock Space
3.1. Term-Document Term-Term and Document-Document Arrays 3.2. SVD, Vector Inner Product and Metric Tensor 3.3. Term-Frequency Fock Space and Metric Tensor for GF-example 3.4. Geometric Meaning of Metric Tensor in Term Frequency Space
Appendix A: The Grossman-Frieder example Appendix B: More on Operators in Fock Space
1. The Classical IR Models and Fock Spaces
In this section, we first give detailed applications of Dirac notation for the three classical models: vector space model, Boolean model and probabilistic model in their classical ways. Then we introduce Fock space as a unified way to represent the above models.
1.1. The Vector Space Model and Weighted Term Vector Space
Suppose we have t-independent terms in our collection, we can think of them as othonormal vectors in a t-dimensional real vector space:
(1.1.1a)
In Dirac notation, we can define a set of the orthonormal vectors ([1], pages 192-195):
(1.1.1b)
Here, is called a ket; is its Hermit conjugate (or, transpose for real vector), and is called a bra; is a bracket, the inner product of two vectors. More about Dirac notation can be found in Ref [19] and [20].
Because any vector in the term-document space (i.e., terms, documents and queries) can be uniquely expanded with respect to the terms, we say that the terms construct a basis of the space. Moreover, if the expansion coefficients are uniquely determined by the inner product of document (and query) with term, the completeness can be written as:
(1.1.1c)
Now we can represent a query vector q and document (μ=1, 2…N) as: (1.1.2a)
Here, and are called term weights of a query or a document with respect to the ith term. They actually define the inner product of a vector (or a query) with a term ([2], page 29; [3], page 15):
(1.1.2b) Note that we have used the fact that, for two real vectors,
This is the classical vector space model (VSM), proposed by Salton et al ([4, 5]). We call the vector space spanned by these t base-vectors of Eq. (1.1.1b) a Weighted Term Vector Space, or WT-space for short. The weights can be calculated based on different schemes, usually involving ([2], page 29; [3], page 15) following parameters:
: The frequency of i-th term in document (1.1.3a) : The number of documents containing i-th term (1.1.3b)
: The length (or word count) of the -th document (1.1.3c)
: Number of all documents in the collection (1.1.3d)
(1.1.3e)
: The frequency of i-th term in the query ([2], page 29) (1.1.3f)
In reference [3], the following formula is used to calculate idf, and :
(1.1.4a)
(1.1.4b)
(1.1.4c)
Many variations on how to compute weights have been done. One good performer is identified as ([3], page 17):
(1.1.4d)
After we have computed the weights, we now can calculate the relevance or the Similarity Coefficient (SC) of document with respect to query q. In classical vector model, SC is the cosine of the angle between the two vectors, ([2], page 27), which can be written as:
(1.1.5)
Here, using (1.1.2a, b) and (1.1.1c), we have:
(1.1.6)
(1.1.7a)
(1.1.7b) In many cases, we want to normalize and , so that: (1.1.8)
We see that the normalized WT-space is a bounded t-dimensional continuous space over the field of [0, 1], restricted in the unit cubes:
(1.1.9)
Note that, the vectors restricted by Eq. (1.1.9) do not form a vector space, because their inverse elements are not included, and they do not close to vector addition. But they do form a subspace, closed to retrieval-related operations. We call such space a retrieval-closed space. Actually, this space is better to be classified as a Fock space (see Section 1.3).
Up to now, the only properties (or assumptions) we know about the base vectors are in Eq. (1.1.1). These assumptions may be relaxed or violated in other models. We also have to define the rules to calculate the inner product of document and query with term vector (the weights), for example, by Eq. (1.1.4).
If we following the discussion in Ref [19], we can rewrite Eq. (1.1.6) using the trace operation: (1.1.10) We accept is as Relevance Coefficient (the cosine law), while in Ref [19], the related probability is given by (page 87) the cosine-squared law:
(1.1.11)
In reference [3], a simple example is used throughout that book. To make it convenient for readers, we will reuse this example and restate the example ([3], page 15). The example, referred to GF-Example from now on, has a collection of three Documents and one Query as described in Appendix A.
To avoid unnecessary confusion, we use the following conventions for labeling indexes of vectors or tensors:
Index Convention:
1.2. The Classical Boolean Model and Boolean Term Vector Space
The classical Boolean model is discussed in [2], §2.5.2. Here we want to use a vector space to describe this model.
Assume that the term-document and term-query weights are all binary, i.e.:
(1.2.1)
Now we introduce new vector space to represent documents and query in this space. Each vector is a director product of t 2-dimentional vector. This space has M = points. We call this vector space a Boolean Term Vector Space, or BT-space for short. Suppose we have 5 independent terms, and a sample vector has three terms: first, second and the fifth. Then in the BT-space, this vector can be represented as:
(1.2.2a)
Here we have used an explicit representation of each 2D factor space. They are chosen as eigenvectors of an occupation operator:
(1.2.2b)
The 2-dimentional vector looks similar to the spin-1/2 vector representation in quantum mechanics (QM). Only difference is, in QM, the base vectors usually are common eigenvectors of operators and , corresponding to spin-up and spin-down states (in natural units, ):
(1.2.3a)
Using these two states as basis, we have their matrix expressions:
(1.2.3b)
Comparing (1.2.2b) and (1.2.3b), we see the following relations:
(1.2.3c)
In BT-space, the basis in equation (1.1) now can be represented as a set of t elements of the form:
(1.2.4a)
And we have t occupation operators:
(1.2.4b)
This means that acts on the l-th 2-dimentional vector of the product; if it is |1>, returns an eigenvalue 1, otherwise returns 0. Therefore we can think of the t base vectors as the common eigenvectors of the t occupation operators. We call it occupation operator, because its eigenvalues are similar to the occupation number of a system of fermions (see §1.3).
A document now can be represented as:
(1.2.5)
The documents in GF-Example now can be represented as:
(1.2.6a)
Now let us assume that our binary query is “ ”, i.e.:
(1.2.6b)
Then we can see only is relevant, because it has the sixth and ninth term but not has the fifth term as the query requires. In other words, the relevant documents of this query are in the following set (or a concept):
(1.2.6c)
Using the vector space, we can also think that any relevant document is a common eigenvector of occupation operators and such that:
(1.2.6d)
Our BT-space is very close to what is used by the Generalized Vector Space, introduced by Wang, Ziarko, and Wong [6]. The main difference is that they consider the space is of dimensional, and introduce base vector to represent a term vector and term-term correlations. In our case, we rather think it is a product of t factor spaces, which is spanned by the eigenvectors of the occupation operator g. This factor space is 2-dimesional for Boolean model, but can be extended easily, as described in next sections (see §1.3 and §2.1).
We see that the BT-space is a bounded, finite and t-dimensional discrete space over the field of {0, 1}, restricted to the vertices of the unit cubes in our WT-space:
(1.2.7)
Again note that, the vectors defined by Eq. (1.2.7) do not form a vector space, but a retrieval-closed space of vectors. It is also a Fock space, as we will see in next section.
Following the discussion in [19] (pages 56-60), we see that our occupation operator is a projector, and can be written as:
(1.2.8)
1.3. Fock Spaces and Occupation Number Representations
The vectors like (1.2.6a) remind us of the Occupation Number Representation (ONR) ([1], page 566) in a multi-particle system:
(1.3.1)
Here is the number of particles occupying the state (orbital). This vector space is called Fock space. For fermions (e.g., electrons, protons…), can only be 0 or 1. Our BT-space is also a Fock space, and its representation can be called as Boolean Term Occupation Number Representation (BT-ONR), in which the number can have only value 0 or 1 for a given term. The occupation operator now can be interpreted as Term Occupation Number Operator. Its eigenvalue is 0 or 1 in BT-space. Because any term, word group, sentence, paragraph, document or query is represented by one of the M = vectors of the form (1.3.1), we can also think of TB space as a finite, discrete set of points (or elements). Each point is a concept. The interesting example is the point representing the vocabulary, or all distinct terms, of the collection ([2], page 174):
(1.3.2)
The base vector (1.2.3) now can also be written as:
(1.3.3)
They form a subset of the t terms, each represent one term. Here we introduce the t-plet notation of the t base vectors (points) in the Fock space:
(1.3.4a)
Note that, in this notation, the addition of two t-plets is actually their union. For example, in our 5-term space, a document vector can be written as: (1.3.4b)
If we allow the term number to be any non-negative integer (or natural number), like the term-frequency in a document, then we have a new representation of the classic vector space: a Term Frequency Fock Space, or TF-space for short, which is similar to ONR for Bosons in Quantum mechanics (e.g., photons, mesons…).
The number vector (1.3.4a) can now be generalized to:
(1.3.5)
The occupation operator now has such a property:
(1.3.6)
In this representation, the three documents and the query in our GF-Example now can be written as: (1.3.7a)
Using term vectors in Eq. (1.3.3) as our base, we can represent the above document vectors and the query vector in columns as follows:
(1.3.7b)
Note that, in this notation, the addition of two t-plets is actually the addition of number vectors. For example, in a 5-dimetional term space, a document vector can be written as:
(1.3.8)
Now we see that the TF-space is a retrieval-closed space of bounded t-dimensional discrete vectors, restricted on the vertices of the unit cubes in our WT-space:
(1.3.9)
In TF-space, we do not use vector addition of documents, but we do need to define inner product, which can be derived from their correspondence in WT space:
(1.3.10)
We will see that the TF-space and their representations will greatly simplify the description of the so-called Latent Semantic Indexing Model (see §3). More about Operators in Fock space is given in Appendix B.
1.4. The Classical Probabilistic Model and Term-Query Probability Fock Space
Assume that the term-document and term-query weights are all binary, as in eq. (1.2.1), and assume that is the set of relevant documents for a query and is the irrelevant document for the query. Then we may modify the identity matrix in eq. (1.1.1) to including a probability factor with respect to q, R and : (1.4.1)
Here and may be computed using formulas like ([2], page 32):
(1.4.2)
where is the probability when term is present in a document randomly selected from the set and is the probability when is resent in a document randomly selected from the set . Usually, in the beginning, the two probabilities are assigned as constants for all terms, for example ([2], page 33):
(1.4.3)
Then, based on the retrieved documents, one can improve the initial ranking.
The Similarity Coefficient now can be calculated as:
(1.4.4)
The reason that here we can use , instead of , is that we are limited in the subset of terms in query , and all other terms , not contained in , are orthogonal to , i.e., Because this space is restricted to subspace spanned by , we may call this space as Term-Query Probability Fock Space, or TQP-space for short.
In many cases, we want to normalize and , as in Eq. (1.1.8). Now suppose that the query is related to m terms. Then the TQP –space is an m-dimensional subspace of the WT-space as described by Eq, (1.1.9):
(1.4.5)
2. The Alternative IR Models
2.1. The Fuzzy Set Retrieval and Fuzzy Boolean Term Fock Space
In classical Boolean Model, a document either has a term or does not have the term. This fact is represented in the values 0 or 1 in the vectors of (1.2.6a). A document is either relevant or irrelevant to a query. This fact is reflected in the set expression (1.2.6c). The basic assumption can be seen in Eq. (1.2.2b), that is, all term states are eigenstates of occupation operator.
An interesting case in QM is that if a spin state is a linear combination of the up and down status. Then this state is not an eigenvector of anymore. We can only predict its “average” value (assume the state vector is normalized):
(2.1.1)
Because can have eigenvalue only -½ or ½, its average value in the range of [-½, ½]. Based on Eq. (1.2.3c), we can think that if there is dependence between terms, we may assign a fuzzy number to occupation operator for i-th term in the -th document as (assume the document vector is normalized):
(2.1.2)
Because can have eigenvalues only 0 or 1, its average value in the range of [0, 1].
This is very mush similar to fuzzy set theory, (see [2], page 35 and its Ref. [846]), where we can have a degree of membership for each term in a document. This can be done by using a map in our 2D space (remember, each 2D space is for one term):
(2.1.3)
For a document vector, we have the following mapped fuzzy document vector: (2.1.4)
The membership of i-th term in j-th document, , can be calculated, e.g., using following formula (see [3], page 86 and our notation in Eq. (1.1.3):
(2.1.5)
In our GF-Example in §1.1.1, we have:
.
Hence, the term gold has a membership in first document as:
Other memberships are listed in table 2.1 9(see [3], page 86).
Table 2.1: Term Membership in Documents ( )
Using our notation, the fuzzy document vectors can be written as:
We call this as a Fuzzy Boolean Term Fock Space, or FBT-space, which can be thought as an extension of TF-ONR by mapping Frequency to a real number between 0 and 1. Again, it is a retrieval-closed space of vectors.
To get the membership of i-th term in j-th document, we can define a new fuzzy occupation operator and a Fuzzy Membership function :
(2.1.4)
Note that the M-function should satisfy the fuzzy set operation rules ([2], page 35 and [3], page 85):
(2.1.5)
Now let us calculate the membership of documents relative to the following query ([3], page 87):
A more explicit way to consider term-term correlation is to introduce a correlation matrix (see [2], page 36 and its Ref. [616]). It can be represented by a matrix representation of a correlation operator:
(2.1.6a)
where is defined in Eq. (1.1.3b), and is the documents which contains both terms. Then the membership of i-th term in -th document can be computed as:
(2.1.6b)
In this approach, the fuzzy OR operation defined in (2.1.5) is replaced by an algebraic sum, implemented as a complements of a negative algebraic products, and the fuzzy AND operation in (2.1.5) is computed using algebraic product. For example:
(2.1.7)
To use above set operation rules, one should first decompose the query concepts in a distinctive normal form, as a union of disjunctive concept vectors (see [2], pages 36-37).
In any case, it seems that, using FBT-space can greatly simplify the expressions and calculations for fuzzy set examples. Based on our discussion, FBT-space is a retrieval-closed space of bounded t-dimensional continuous vectors, as described by Eq. (1.1.9).
Another way to improve Boolean search is to rank the relevance document based on its closeness to a query, using Extended Boolean Model, introduced by Salton, Fox and Wu [7, 8] (see [2], page 38, [3], page 67 and [5]).
First, we assume that all terms in a document or a query are assigned with weights as in classical vector model, described in §1.1. All weights are normalized to be in the range of [0, 1].
Next, the least or most desirable point is decided based on the operation of the Boolean query (union or join). If the query is a union of m terms, we will have the least desirable point; if the query is a joint of m terms, then we will have the most desirable points. To describe such points, we restrict ourselves to a subspace, spanned by the terms contained in the query. We call this space the q-space (like in the classical probabilistic model). To simplify our formula, we assume that the first m terms are contained in the query. Now we can express the Identity operator in the m-dimensional q-space by: (2.2.1)
In this subspace, the query and a document is expressed in the WT-space (Weighted Term Vector Space) as:
(2.2.2)
If the query is a union of m terms, (2.2.3a)
then the least desirable point is the origin of the weighted space ([2], page 39):
(2.2.3b) The same vector, if represented in our TF-space (or BT-space), will be:
(2.2.3c)
If the query is a joint of m terms: (2.2.4a)
We can see that the most desirable point is the vector of the highest weights ([2], page 39):
(2.2.4a)
The same vector, if represented in our TF-space (or BT-space), will be:
(2.2.4c)
Now we need define a measure or a distance in the space, in order to calculate the distance of the document from such point. According to [7.8], we can define the normalized distance between two vectors in the m-dimensional q-space with a parameter p by:
(2.2.4) This is a normalized form of the Minkowski distance of order p (or p-norm distance) in a Euclidean space, as an example of metric spaces [9].
With the above descriptions, we can simplify the Similarity Coefficients (SC) formulas as follows.
(2.2.5a)
(2.2.5b)
If p = 1, the distance is the difference of the two vectors in m-dimensional vector space; if p = 2, the distance is for an m-dimensional Euclidian space; if p = ∞, Eq. (2.25) return the result of the original Boolean query.
We can also include the weights of query in the calculation of distance ([3], page 68). Then Eq. (2.2.4) becomes: (2.2.6)
We call the space the Extended Boolean Term Fock Space (EBT-space). Based on our discussion, the EBT-space is a bounded t-dimensional continuous metric space: it is a retrieval-closed space of vectors as described by Eq. (1.1.9) and it is also a metric space with a p-norm (2.2.4) or (2.2.6) as its distance function. No inner product is need here.
2.3. Term-Term Correlation and the Document Fock Space
Because the existence of term-term correlations, we cannot say terms are independent. This means that the term vectors in Eq. (1.1.b) are not orthogonal to each other anymore:
(2.3.1a)
Note that the completeness of terms, as described in Eq. (1.1.1c) still holds as long as the expansion of documents and query are unique with respect to defined inner products. In this case, we still have:
(2.3.1b)
There are many ways to compute term-term relationships. The Generalized Vector Model was proposed by Wong, Ziarko and Wong in 1985 [6]. They considered the space spanned by the vectors similar those described in Eq. (1.2.6), introduced orthonormal vectors as the bases of the vector space, expressed terms as linear combinations of these base vectors, and calculated term-term correlation based on such term expressions. More details can also be seen in [2: pages 41-44].
Here we discuss a query expansion model based on a global similarity thesaurus which is constructed automatically ([10], and [2], page 131-133]). Because the conditions in Eq. (2.3.1), we cannot use the base vectors in (1.1.1b) to represent our vector space. Instead, we expand term vectors with respect to documents:
(2.3.2)
Assume any term is at least in one document and no two documents are identical in term frequency, so term vector can be uniquely expanded with respect to document vectors. This is a very strong requirement: the Term-Document matrix defined in Eq. (3.1.1) need have a rank of t. In this way, we can think that the document vectors form a basis of N-dimensional Fock space, with the inner product of term-document defined in (2.3.2):
(2.3.3)
The weights in Eq. (2.3.2), now the document occupation number of terms, are calculated using the following formula ([2], page 132),
(2.3.4)
where is defined in Eq. (1.1.3a), is the maximum value of all for a given , and is the inverse term frequency for document , defined by:
(2.3.5) Here is the number of distinct terms in document .
Now we can express the term-term correlation factor as (identical to Eq. (5.12) in [2], page 132):
(2.3.6)
Although terms are not an orthonormal system, we still can define the query vector as a linear combination of terms contained in the query ([2], page 133):
(2.3.7)
Here, the weights are calculated similarly to Eq. (2.3.5), but they are not equal to the inner product of term-query. Instead, the inner product of a query with a term is computed using (2.3.7) and (2.3.6) as:
(2.3.8)
Now we can derive our expression for the Similarity Coefficient as:
(2.3.9)
This equation is identical to the one on page 134, Ref [2].
We call the vector space spanned by document vectors defined in (2.3.3) as Document Vector Space (DV-space), which is an N-dimensional vector space with base vector (2.3.3), and its inners product of document and query with term as (2.3.2) and (2.3.8). Based on above rules, we can then calculate the term-term correlations as in (2.3.6).
We see in this model, document and query are treated differently, because they have different inner product rules with terms. In next section, we will see a more natural way of introduce term-term interaction in which document and query would be treated in the same way, unified by a metric tensor derived using SVD.
3. Latent Semantic Indexing Model and SVD
In WT-space of classical vector models, we have the basic assumption that the term vectors form a complete orthonormal bases as in Eq. (1.1.1b). In reality, terms are not independent vectors, because of the existence of the term-document relations.
This situation is very much like the situation in the quantum system of the Hydrogen atom when neglecting the orbital-spin (L-S) interaction ([1], pages 549-554). If we neglect the L-S interaction, the Hamiltonian (H) of the system has eigenvector which are also the common eigenvectors of the orbital angular momentum operators (L2, Lz) and the spin angular momentum (S2, Sz). Any two of them are orthogonal if anyone of the four eigenvalues (L2, Lz, S2, Sz) is different. But because of the L-S interaction, they become dependent and we have no such common eigenvectors anymore. Instead, we have to introduce the total angular momentum (J = L + S), to find the common eigenvectors of (J2, L2, S2, Jz), which give us the fine structure of the Hydrogen atom ([1], page 554-555).
3.1. Term-Document, Term-Term and Document-Document Arrays
In Latent Semantic Indexing (LSI) Model singular value decomposition (SVD), the key assumption is that the document-term dependence causes both term-term and documents-document dependences ([2], pages 44-45; [3], pages 70-73]; [11-12]). The document-term dependence is nothing else but the frequency of i-th term in the -th document, , as defined in Eq. (1.1.3a). We also have their representations in Eq. (1.3.7) in our TF-space for the GF-examples. This relation can be viewed as the definition of inner product between a document and a term, and represented by a t x N matrix A (the term-document matrix) as follows:
(3.1.1)
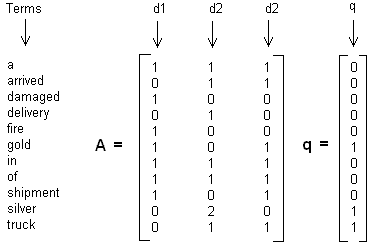
Here we have used the document vectors as the columns in the matrix. From now on, we assume that t > N. Apply to our GF-example, we have the following three document vectors, the term-doc matrix and the query vector.
[12]-4: Figure 2. Term-document matrix and query matrix example
The term-term interaction is defined by a t x t matrix L (called Left matrix):
(3.1.2)
Here we have used the transpose of document vectors as the rows in the matrix. Note that the elements of matrix L are similar to (2.3.6); the difference is the definition of the inner product of term and document.
The document-document interaction is defined by N x N matrix R (called Right matrix):
(3.1.3)
Because both L and R are real symmetric matrices, they both have real, complete and orthogonal eigenvectors with the same set of real, non-negative eigenvalues ([1], pages 199-204; [13], pages 321-325). Here are their normalized forms:
(3.1.4)
3.2. SVD, Vector Inner Product and Metric Tensor
Now we can apply the Singular Value Decomposition (SVD) of matrix A to use the eigenvectors of both L and R:
(3.2.1) Here, U and V are orthogonal matrices, the columns of the t x N matrix U are the N new term eigenvectors u, the columns of N x N matrix V are the new document eigenvectors v, and the N x N matrix S is a diagonal matrix with its diagonal elements Si = (the singular values) as the square root of the eigenvalues of M or MT. We can arrange Si such that S1 > S2 > S3 > … SN.
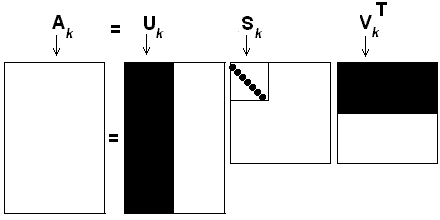
One of the advantages of SVD is that, in most cases, we do not need to use eigenvectors of zero eigenvalues (usually, there are many of them), and we can also keep only r non-zero singular values to reduce the ranks of all matrices to r, without losing much of the accuracy:
(3.2.2)
This is referred to Reduced SVD (RSVD). We can visually explain the reduction by the following figure (a copy of Figure 8, tutorial 3, Ref. [12], where k is used as our r).
[12]-4: Figure 8. The Reduced SVD or Rank k Approximation
Using the Dirac notation, we can express (3.2.2) as:
(3.2.3) Here we have used following notations:
(3.2.4a)
This means that:
(3.2.4b)
Also note that here the new document vectors are reduced to r-dimensional.
A very important equation derived from Eq. (3.2.1) is ([12], tutorial 4):
(3.2.5a) Using Eq. (3.1.1) and (3.2.4a), we can express (3.2.5a) in reduced form as:
(3.2.5b)
This equation tells us how we can transform original document vector to new vector: :
(3.2.6a)
Since the query vector is treated like a document vector, we can compute the new query vector as: (3.2.6b) Eq. (3.2.6) give us a geometrical interpretation of the transformation: the new document vector is represented in a new base of the new term vectors ( , eigenvectors of L); its ith component is its inner product with corresponding new term vector , scaled by a factor of 1/Si. So we can say the new document is the result of a rotation (from k to k’) plus a scaling. Then, the inner product of the two new vectors can be derived from Eq. (3.2.6) as:
(3.2.7)
Finally, the ranking of documents now can be calculated using the Cosine low (1.1.5), or:
(3.2.10)
Now let us introduce a metric tensor to simplify our calculations. We can rewrite Eq. (3.2.7) in a more concise form: (3.2.11)
Here, we have defined our Riemannian metric tensor as:
(3.2.12)
In this way, we actually interpret the inner product of two vectors on the tangent space of an r-dimensional Riemannian Manifold [16][19]:
(3.2.13) The norm of the vector can be calculated as the square root of its self- inner product. Eq. (3.2.10) now can be rewritten as:
(3.2.14)
3.3. Term-Frequency Fock Space and Metric Tensor for GF-example
We see that, from Eqs. (3.2.11-13), to compute the ranking of a document with respect to a query , all we need to do are:
Now let us go over it with our GF-example.
Step 1: we use online tool [14] to calculate L = AAT, the matrix is as follows:
3 2 1 1 1 2 3 3 2 2 2 2 2 0 1 0 1 2 2 1 2 2 1 0 1 0 1 1 1 1 1 0 0 1 1 0 1 0 0 1 1 0 2 1 1 0 1 0 1 1 1 1 1 0 0 2 1 1 0 1 2 2 2 2 0 1 3 2 1 1 1 2 3 3 2 2 2 3 2 1 1 1 2 3 3 2 2 2 2 1 1 0 1 2 2 2 2 0 1 2 2 0 2 0 0 2 2 0 4 2 2 2 0 1 0 1 2 2 1 2 2
Step 2: we use online tool [15] to calculate its eigenvalues and eigenvectors. It has 3 non-zero eigenvalues, their square roots Si are:
{S1, S2, S3} = {4.0989, 2.3616, 1.2737} (3.3.1)
Their corresponding eigenvectors (k’1, k’2,, k’3) are as follow:
[-0.4201, -0.2995, -0.1206, -0.1576, -0.1206, -0.2626, -0.4201, -0.4201, -0.2626, -0.3151, -0.2995]T [-0.0748, 0.2001, -0.2749, 0.3046, -0.2749, -0.3794, -0.0748, -0.0748, -0.3794, 0.6093, 0.2001] T [-0.0460, 0.4078, -0.4538, -0.2006, -0.4538, 0.1547, -0.0460, -0.0460, 0.1547, -0.4013, 0.4078] T
Step 3: we keep all three eigenvectors, i.e., set r = 3 in Eq. (3.2.2); using a simple computer program [18] and Eq. (3.2.12), we get the metric matrix g as follows:
0.0127 -0.0067 0.0195 0.0055 0.0195 0.0072 0.0127 0.0127 0.0072 0.011 -0.0067 -0.0067 0.1149 -0.1217 -0.0366 -0.1217 0.0299 -0.0067 -0.0067 0.0299 -0.0733 0.1149 0.0195 -0.1217 0.1412 0.0421 0.1412 -0.0226 0.0195 0.0195 -0.0226 0.0844 -0.1217 0.0055 -0.0366 0.0421 0.0428 0.0421 -0.0373 0.0055 0.0055 -0.0373 0.0857 -0.0366 0.0195 -0.1217 0.1412 0.0421 0.1412 -0.0226 0.0195 0.0195 -0.0226 0.0844 -0.1217 0.0072 0.0299 -0.0226 -0.0373 -0.0226 0.0446 0.0072 0.0072 0.0446 -0.0747 0.0299 0.0127 -0.0067 0.0195 0.0055 0.0195 0.0072 0.0127 0.0127 0.0072 0.011 -0.0067 0.0127 -0.0067 0.0195 0.0055 0.0195 0.0072 0.0127 0.0127 0.0072 0.011 -0.0067 0.0072 0.0299 -0.0226 -0.0373 -0.0226 0.0446 0.0072 0.0072 0.0446 -0.0747 0.0299 0.011 -0.0733 0.0844 0.0857 0.0844 -0.0747 0.011 0.011 -0.0747 0.1716 -0.0733 -0.0067 0.1149 -0.1217 -0.0366 -0.1217 0.0299 -0.0067 -0.0067 0.0299 -0.0733 0.1149
Step 4: Using the simple computer programs [18] and Eq. (3.2.10 and12), we get the following similarity coefficients:
SC (d1, q) = (d1, q)/|d1|/|q| = -0.2787 SC (d1, q) = (d1, q)/|d1|/|q| = 0.7690 (3.3.2) SC (d1, q) = (d1, q)/|d1|/|q| = 0.5756
We see the ranking of documents are:
d2 > d3 > d1 (3.3.3)
To compare with the results in [3] and [12], we keep only top 2 eigenvectors of L, i.e., set r = 2 in Eq. (3.2.12) and metric matrix g now becomes
0.0114 0.0047 0.0066 -1.0E-4 0.0066 0.0116 0.0114 0.0114 0.0116 -2.0E-4 0.0047 0.0047 0.0125 -0.0077 0.0137 -0.0077 -0.0089 0.0047 0.0047 -0.0089 0.0274 0.0125 0.0066 -0.0077 0.0144 -0.0138 0.0144 0.0205 0.0066 0.0066 0.0205 -0.0277 -0.0077 -1.0E-4 0.0137 -0.0138 0.018 -0.0138 -0.0182 -1.0E-4 -1.0E-4 -0.0182 0.0361 0.0137 0.0066 -0.0077 0.0144 -0.0138 0.0144 0.0205 0.0066 0.0066 0.0205 -0.0277 -0.0077 0.0116 -0.0089 0.0205 -0.0182 0.0205 0.0298 0.0116 0.0116 0.0298 -0.0365 -0.0089 0.0114 0.0047 0.0066 -1.0E-4 0.0066 0.0116 0.0114 0.0114 0.0116 -2.0E-4 0.0047 0.0114 0.0047 0.0066 -1.0E-4 0.0066 0.0116 0.0114 0.0114 0.0116 -2.0E-4 0.0047 0.0116 -0.0089 0.0205 -0.0182 0.0205 0.0298 0.0116 0.0116 0.0298 -0.0365 -0.0089 -2.0E-4 0.0274 -0.0277 0.0362 -0.0277 -0.0365 -2.0E-4 -2.0E-4 -0.0365 0.0724 0.0274 0.0047 0.0125 -0.0077 0.0137 -0.0077 -0.0089 0.0047 0.0047 -0.0089 0.0274 0.0125
Using this metric tensor in Eq. (3.2.13-14), we recalculate the similarity coefficients:
SC (d1, q) = (d1, q)/|d1|/|q| = -0.0552 SC (d2, q) = (d2, q)/|d2|/|q| = 0.9912 (3.3.4)
SC (d3, q) = (d3, q)/|d3|/|q| = 0.4480
The results are almost identical to the results in [3] and [12] ([3], page 73; [12], tutorial 4, Figure 6). Their results are:
SC (d1, q) = (d1, q)/|d1|/|q| = -0.0541 SC (d2, q) = (d2, q)/|d2|/|q| = 0.9910 (3.3.5) SC (d1, q) = (d3, q)/|d3|/|q| = 0.4478
We see that, the order of the ranking of documents is the same as in Eq. (3.3.3) where we use r = 3:
d2 > d3 > d1 (3.3.6)
From the numerical results, we see there is an important characteristic of LSI/SVD: the relevance coefficient can be negative. This means, the angle between the document and the query can be greater than π/2. If we use the cosine squared law as in Eq. (1.1.11) of Ref [19], then the ranking may cause problem.
3.4. Geometric Interpretation of Metric Tensor in Term Frequency Fock Space
In this section we would like to give a brief geometric interpretation on metric tensor, SVD and TF-space of LSI.
We know that in the Cartesian coordinate system of a Euclidian space, the metric has the simplest form:
(3.4.1)
But in other curvilinear coordinate systems (like polar or spherical), metric tensors have different forms, and they can be transformed to each other. But the space is still flat (the curvature is zero). In general relativity (see [17], chapter 3) the metric tensor is the solution of Einstein field equation, representing a curved space by the distribution of matter, modular to general coordinate transformations.
Metric tensor for IR has mentioned in Ref [19] (page 86). Following the notation there, we can rewrite Eq. (3.2.12) as:
(3.4.2)
Here the r-dimensional base vectors have the following components:
(3.4.3) Now Eq. (3.2.13) can be rewrite as:
(3.4.4)
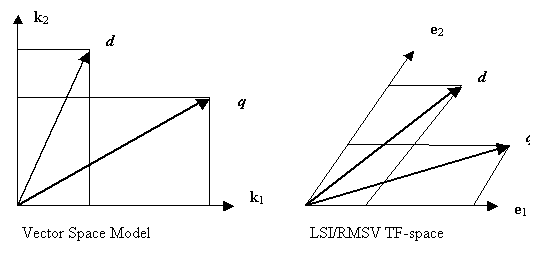
The following are 2D graphic representations of the related vectors.
In short, we have provided a concrete example of metric tensor from LSI. We see that, because of the term-term interaction, the old term coordinate system (in which we have the representation of term-document interaction array) is no longer a Cartesian coordinated system. Actually, SVD finds the new orthogonal coordinate systems (using new term vector k’), and the transformation between the two systems. The existence of the global Cartesian coordinate system shows that the Term Frequency space of LSI is a flat space. This is easy to see, because the metric tensor defined in Eq. (3.2.12) or (3.4.2) is a global constant tensor.
Note that in the Extended Boolean Model we also have used a metric, a distance function as in Eq. (2.2.4). But that is not a Riemannian metric, because it is not a rank-2 tensor and we cannot use it to define inner product of vectors in that space. On the other hand, Riemannian metric can also be used as a distance function, although we use it here only to define the inner product of vectors on the tangent space. Because Term Frequency space is flat, therefore, its tangent space at any point is itself.
We did not introduce metric tensor for weighted term vector space in §1.1, because there we have already assumed no term-term interaction, hence the old term vectors form an orthonormal basis as in Eq. (1.1.1b). In addition, since the weight format is not always proportional to term frequency, as in Eq. (1.1.4d), it is not naturally to make such inner product in a metric tensor form.
We have used Dirac notation and introduced Fock Space to unify the representations of IR models. The classical Boolean model can be described by a Boolean Term Fock space, with occupation number 0 or 1. If we relax the restrictions on the value of occupation number, we can define Fuzzy Boolean Term Fock space (for fuzzy Boolean model), Term Frequency Fock space (For LSI), and Weighted Term Fock Space (for classical vector model). The term vectors in such a Fock space may be orthogonal (as in WT, BT, FBT spaces), but also may not be orthogonal, as in Document Fock space or the TF-space in LSI, where we have applied Dirac notation to SVD, derived a metric tensor and used it to rate documents with respect to a query for the Grossman-Frieder example. We hope our discussion would help to understand, unify and simplify the representations and manipulations of the term, document and query vectors in modern information retrieval.
Appendix A: The Grossman-Frieder example
In reference [3], a simple example is used throughout that book. The example, referred to GF-Example in this article, has a collection of three Documents and one Query as follows:
: “gold silver truck” : “Shipment of gold damaged in a fire” : “Delivery of silver arrived in a silver truck” : “Shipment of gold arrived in a truck”
Then the parameters defined in Eq. (1.1.3) can be calculated and listed in Table 1.1.
Table 1.1: Term Frequencies ( , and ) and Other Parameters
Here, we calculated idf using equation (1.1.3a) with = 3. Readers can get more detailed information in Ref. [3] about calculating weights for this example using Eq. (1.3.3) ([3], pages 16).
Appendix B: More on Operators in Fock Space
Fock space describes the states of “many-particle” systems (our documents), it is the space used in second quantization or quantum field theory. In Fock space, the basic representation is the ONR, and the basic operators are creation and annihilation operators (([1], page 576). They add or remove a term in a given document.
For TF-space (documents of terms as ‘Bosons”), they have the following properties:
(B.1)
Here we have used the definition of communication relation:
(B.2)
For BT-space (documents of terms as ‘Fermions”), their properties are:
(B.3)
Here we have used the definition of anti-communication relation:
(B.4)
The occupation number can be expressed as follows ([1], page 575):
(B.5)
It has eigenvalues for Bosons and Fermions because they have different commutation rules (B.2) and (B.4). We are not going to use operators other than the occupation number operator. But it is worthwhile to know that, in Fock space, all operators can be expressed in terms of creation or annihilation operators. For example, if ĥ is a single term operator, then an operator of the system (a document) can be written as:
(B.6)
Note that the term states can have a continuous spectrum; in this case, the operator can be written is:
(B.7)
These features might be useful to deal with document updating or down-dating, and also with relations to non-text collections.
The Hilbert space and operators introduced in Ref. [19] are mainly based on “single–particle” states or first quantization. We see that there is a homomorphism between the document vectors in classical Vector Space Model and in TF-space, so we can use either way to investigate them. But as for classical Boolean Model, the BT Fock space maybe is the most natural one to use.
References
[1]. Herbert Kroemer. Quantum Mechanics, for Engineering, Material Science and Applied Physics. Prentice Hall, 1994. [2]. Ricardo Baeza-Yates and Berthier Riberto-Neto. Modern Information Retrieval. Addison Wesley, New York, 1999. [3]. David A. Grossman and Ophir Frieder. Information Retrieval, Algorithm and Heuristics, 2nd Edition. Springer, 2004. [4]. G. Salton and M.E. Lesk, Computer evaluation of indexing and text processing. Journal of the ACM, 15 (1): 8-16, Jan., 1968. [5]. G. Dalton. The SMART Retrieval System – Experiments in Automatic Document Processing. Prentice Hall Inc., Englewood Cliffs, NJ, 1971. [6]. S. K. M. Wong, W. Ziarko, and P. C. Wong, Generalized vector space model in information retrieval. In Proc. 8th ACM SIGIR Conference on Research and Development in Information Retrieval, pages 18-25, New York, USA, 1985. [7]. Gerard Salton, Edward A. Fox, and Harry Wu, Extended Boolean information retrieval. Communications of the ACM, 26(11):1022-1036, November 1983. [8]. Gerard Salton. Automatic Text Processing. Addison-Wesley, 1989. [9]. Stephen Willard. General Topology, page 16, Dover Publications Inc., New York, 2004. Also see: http://en.wikipedia.org/wiki/Distance#Norms [10]. Yonggang Qiu and H. P. Frei. Concept based query expansion. In Proc. 16th ACM SIGIR Conference on Research and Development in Information Retrieval, pages 160-169, Pittsburg, USA, 1993 [11]. G. W. Furnas, S. Deerwester, S. T. Dumais, T. K. Landauwer, R. A. Harshman, L. A. Streeter, and K. E. Lochbaum. Information retrieval using a singular value decomposition model of latent semantic structure. In Proc. of the 11th annual International ACM SIGIR conference on Research and Development in Information Retrieval, pages 465-480, 1988. [12]. E. Gasia. SVD and LSI Tutorial 1-4. Starting from: http://www.miislita.com/information-retrieval-tutorial/svd-lsi-tutorial-1-understanding.html [13]. Steven J. Leon. Linear Algebra with Applications. 4th edition, Macmillan College Publishing Company, Inc, 1994. [14]. Matrix multiplication: http://www.uni-bonn.de/~manfear/matrixcalc.php [15]. Matrix eigenvalues and eigenvectors: http://www.bluebit.gr/matrix-calculator/ [16]. Riemann Metric: http://en.wikipedia.org/wiki/Riemannian_metric [17]. S. Weinberg. Gravitation and Cosmology. John Wiley, 1972. [18]. S. Wang. A Java program at: PlayMatrix.java [19]. Keith Van Rijsbergen. The Geometry of Information Retrieval. Cambridge, 2004. [20]. Lorenzo Sadun. Applied Linear Algebra: The Decoupling Principle. Prentice Hall, 2000.
|